基于用户的协同过滤概述¶
协同过滤¶
介绍¶
协同过滤推荐算法是诞生最早,并且较为著名的推荐算法。主要的功能是预测和推荐。算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。
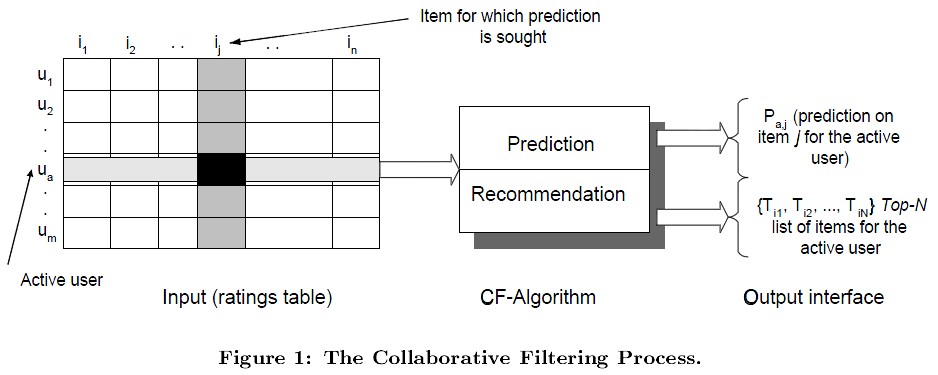
协同过滤(Collaborative Filtering)作为推荐算法中最经典的类型,包括在线的协同和离线的过滤两部分。所谓在线协同,就是通过在线数据找到用户可能喜欢的物品,而离线过滤,则是过滤掉一些不值得推荐的数据,比如推荐值评分低的数据,或者虽然推荐值高但是用户已经购买的数据。
协同过滤的模型一般为m个物品,m个用户的数据,在预测过程中只有部分用户和部分数据之间是有评分数据的,其它部分评分是空白,此时我们要用已有的部分稀疏数据来预测那些空白的物品和数据之间的评分关系,找到最高评分的物品推荐给用户。
步骤¶
1)收集用户的爱好
要从用户的行为和偏好中发现规律,并基于此给予推荐,如何收集用户的偏好信息成为系统推荐效果最基础的决定因素。用户有很多方式向系统提供自己的偏好信息,而且不同的应用也可能大不相同。
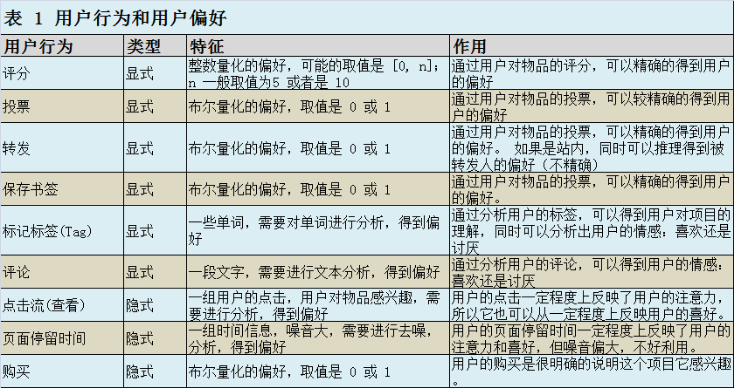
- 将不同的行为分组:一般可以分为“查看”和“购买”等等,然后基于不同的行为,计算不同的用户 / 物品相似度。类似于当当网或者 Amazon 给出的“购买了该图书的人还购买了 ...”,“查看了图书的人还查看了 ...”。
- 根据不同行为反映用户喜好的程度将它们进行加权,得到用户对于物品的总体喜好。一般来说,显式的用户反馈比隐式的权值大,但比较稀疏,毕竟进行显示反馈的用户是少数;同时相对于“查看”,“购买”行为反映用户喜好的程度更大,但这也因应用而异。
将不同的行为分组:一般可以分为“查看”和“购买”等等,然后基于不同的行为,计算不同的用户 / 物品相似度。类似于当当网或者 Amazon 给出的“购买了该图书的人还购买了 ...”,“查看了图书的人还查看了 ...”。 根据不同行为反映用户喜好的程度将它们进行加权,得到用户对于物品的总体喜好。一般来说,显式的用户反馈比隐式的权值大,但比较稀疏,毕竟进行显示反馈的用户是少数;同时相对于“查看”,“购买”行为反映用户喜好的程度更大,但这也因应用而异。
收集了用户行为数据后,进行组合不同用户行为之前,我们还需要对数据进行一定的预处理,其中最核心的工作就是:减噪和归一化。进行了预处理后,根据不同应用的行为分析方法,就可以选择我们使用上述所提到的分组或者加权处理,之后我们可以得到一个用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,值是用户对物品的偏好,一般是 [0,1] 或者 [-1, 1] 的浮点数值。
2)找到相似的用户或者物品
当已经对用户行为进行分析得到用户喜好后,我们可以根据用户喜好计算相似用户和物品,然后基于相似用户或者物品进行推荐,这就是最典型的 CF 的两个分支:基于用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。 然后在这其中最重要的就是相似度的计算了,常用的相似度的计算有:
- 向量空间余弦相似度(Cosine Similarity)
- 皮尔森相关系数(Pearson Correlation Coefficient)
- Jaccard相似系数(Jaccard Coefficient)
- 调整余弦相似度(Adjusted Cosine Similarity)
(★补充)距离计算和相似度计算区分:
-
距离度量(Distance)用于衡量个体在空间上存在的距离,距离越远说明个体间的差异越大。
-
相似度度量(Similarity),即计算个体间的相似程度,与距离度量相反,相似度度量的值越小,说明个体间相似度越小,差异越大。
常用的距离计算:
- 欧几里得距离(Euclidean Distance)
- 明可夫斯基距离(Minkowski Distance)
- 曼哈顿距离(Manhattan Distance)
- 切比雪夫距离(Chebyshev Distance)
- 马哈拉诺比斯距离(Mahalanobis Distance)
注意:在实际的应用中距离度量和相似度度量的计算方法都可以用于相似度的计算!!!
3)推荐
根据用户的喜欢程度(评分)与得到的相似矩阵的计算结果进行排序(选取相似度最高的前k个)推荐。
4)模型评估
- 均方误差(MSE)
- 均方根误差(RMSE)
- 平均绝对误差(MAE)
- 标准差(SD)
基于用户的协同过滤¶
介绍¶
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。下图给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 - 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。

推导¶
1)(建立物品-用户的倒查表)
2)建立用户-用户的稀疏矩阵(共现矩阵/同现矩阵)
3)建立相似矩阵(相似度计算:找到和目标用户兴趣相似的用户集合)
4)推荐(构建推荐矩阵:找到这个集合中用户喜欢的,且目标用户没有听说过的物品推荐给目标用户)
实例推导:


代码实现¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | from operator import * import math #例子中的数据相当于是一个用户字典{A:(a,b,d),B:(a,c),C:(b,e),D:(c,d,e)} #我们这样存储原始输入数据 dic={'A':('a','b','d'),'B':('a','c'),'C':('b','e'),'D':('c','d','e')}#简单粗暴,记得加'' #计算用户兴趣相似度 def Usersim(dicc): #把用户-商品字典转成商品-用户字典(如图中箭头指示那样) item_user=dict() for u,items in dicc.items(): for i in items:#文中的例子是不带评分的,所以用的是元组而不是嵌套字典。 if i not in item_user.keys(): item_user[i]=set()#i键所对应的值是一个集合(不重复)。 item_user[i].add(u)#向集合中添加用户。 C=dict()#感觉用数组更好一些,真实数据集是数字编号,但这里是字符,这边还用字典。 N=dict() for item,users in item_user.items(): for u in users: if u not in N.keys(): N[u]=0 #书中没有这一步,但是字典没有初始值不可以直接相加吧 N[u]+=1 #每个商品下用户出现一次就加一次,就是计算每个用户一共购买的商品个数。 #但是这个值也可以从最开始的用户表中获得。 #比如: for u in dic.keys(): # N[u]=len(dic[u]) for v in users: if u==v: continue if (u,v) not in C.keys():#同上,没有初始值不能+= C[u,v]=0 C[u,v]+=1 #这里我不清楚书中是不是用的嵌套字典,感觉有点迷糊。所以我这样用的字典。 #到这里倒排阵就建立好了,下面是计算相似度。 W=dict() for co_user,cuv in C.items(): W[co_user]=cuv / math.sqrt(N[co_user[0]]*N[co_user[1]]) return W def Recommend(user,dicc,W2,K): rvi=1 #这里都是1,实际中可能每个用户就不一样了。就像每个人都喜欢beautiful girl,但有的喜欢可爱的多一些,有的喜欢御姐多一些。 rank=dict() related_user=[] interacted_items=dicc[user] for co_user,item in W2.items(): if co_user[0]==user: related_user.append((co_user[1],item))#先建立一个和待推荐用户兴趣相关的所有的用户列表。 for v,wuv in sorted(related_user,key=itemgetter(1),reverse=True)[0:K]: #找到K个相关用户以及对应兴趣相似度,按兴趣相似度从大到小排列。itemgetter要导包。 for i in dicc[v]: if i in interacted_items: continue #书中少了continue这一步吧? if i not in rank.keys():#如果不写要报错,是不是有更好的方法? rank[i]=0 rank[i]+=wuv*rvi return rank if __name__=='__main__': W3=Usersim(dic) Last_Rank=Recommend('A',dic,W3,2) print(Last_Rank) |
基于用户的协同过滤运行结果查看
{'c': 0.4082482904638631, 'e': 0.4082482904638631}
