K-最近邻算法概述¶
介绍¶
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。KNN是一种分类(classification)算法,它输入基于实例的学习(instance-based learning),属于懒惰学习(lazy learning)即KNN没有显式的学习过程,也就是说没有训练阶段,数据集事先已有了分类和特征值,待收到新样本后直接进行处理。与急切学习(eager learning)相对应。
KNN算法的思路是:如果一个样本在特征空间中的k个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
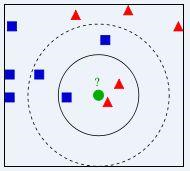
提到KNN,网上最常见的就是下面这个图,可以帮助大家理解。我们要确定绿点属于哪个颜色(红色或者蓝色),要做的就是选出距离目标点距离最近的k个点,看这k个点的大多数颜色是什么颜色。当k取3的时候,我们可以看出距离最近的三个,分别是红色、红色、蓝色,因此得到目标点为红色。
算法步骤¶
步骤描述¶
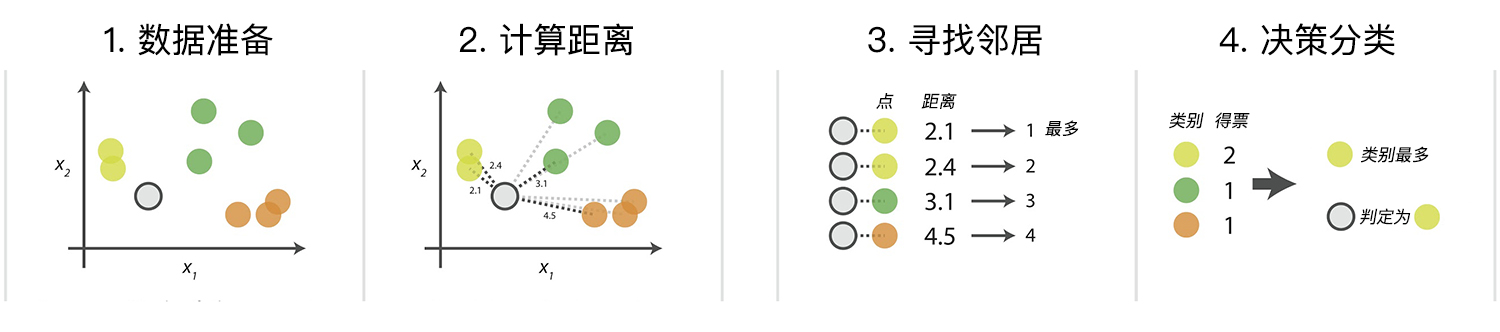
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别(决策依据方法之一)作为测试数据的预测分类。
关于距离的计算¶
这里的距离指的是平面上两个点的直线距离。常用的距离计算公式有:
-
闵可夫斯基距离
-
欧几里得距离
-
曼哈顿距离
-
切比雪夫距离
-
马氏距离
-
余弦相似度
-
皮尔逊相关系数
-
汉明距离
-
杰卡德相似系数
-
编辑距离
-
DTW 距离
-
KL 散度
关于K值的选择¶
K称为临近数,即在预测目标点时取几个临近的点来预测。
K值得选取非常重要,因为:
-
如果当K的取值过小时,一旦有噪声得成分存在们将会对预测产生比较大影响,例如取K值为1时,一旦最近的一个点是噪声,那么就会出现偏差,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
-
如果K的值取的过大时,就相当于用较大邻域中的训练实例进行预测,学习的近似误差会增大。这时与输入目标点较远实例也会对预测起作用,使预测发生错误。K值的增大就意味着整体的模型变得简单,也就是容易发生欠拟合;
-
如果K=N的时候,那么就是取全部的实例,即为取实例中某分类下最多的点,就对预测没有什么实际的意义了;
为此我们可以这样取K的值:
-
从k=1开始,使用检验集估计分类器的误差率。重复该过程,每次K增值1,允许增加一个近邻。选取产生最小误差率的K;
-
一般k的取值不超过20,上限是n的开方,随着数据集的增大,K的值也要增大;
-
K的取值尽量要取奇数,以保证在计算结果最后会产生一个较多的类别,如果取偶数可能会产生相等的情况,不利于预测。
关于决策依据/规则¶
最常用的决策规则是:
-
多数表决法(更常用):多数表决法类似于投票的过程,也就是在 K 个邻居中选择类别最多的种类作为测试样本的类别;
-
加权表决法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大,通过权重计算结果最大值的类为测试样本的类别。
优缺点¶
优点:¶
1)简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归;
2)可用于数值型数据和离散型数据;
3)训练时间复杂度为O(n);无数据输入假定;
4)对异常值不敏感。
缺点:¶
1)计算复杂性高;空间复杂性高;
2)样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);
3)一般数值很大的时候不用这个,计算量太大。但是单个样本又不能太少,否则容易发生误分;
4)最大的缺点是无法给出数据的内在含义。
代码练习¶
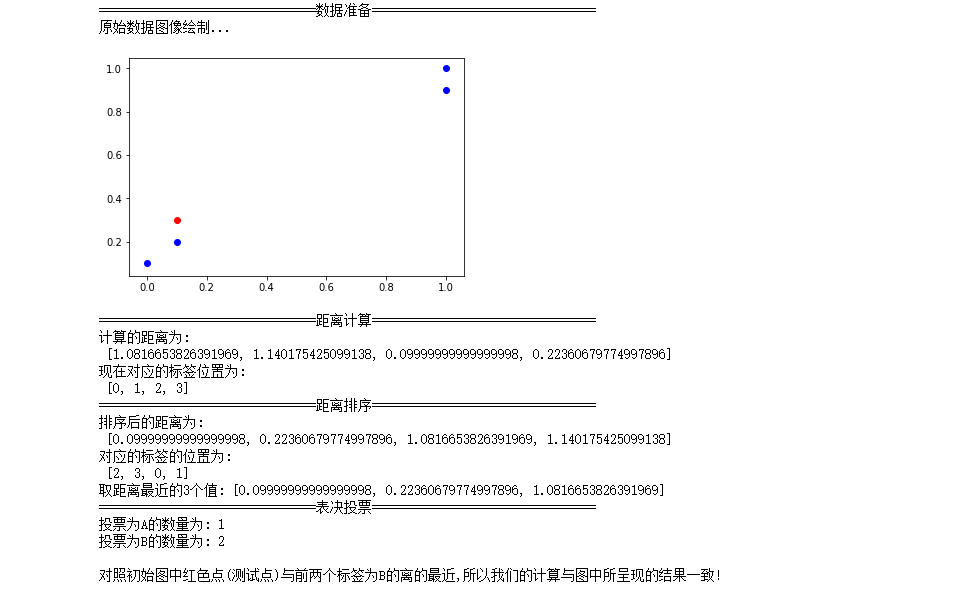
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | #引库 import numpy as np import matplotlib.pyplot as plt from math import sqrt %matplotlib inline #原始数据 data = [[1,0.9],[1,1],[0.1,0.2],[0,0.1]] labels = ["A","A","B","B"] test_data = [[0.1,0.3]] #绘制原始数据散点图 print("===============================数据准备================================") print("原始数据图像绘制...") for i in range(len(data)): plt.scatter(data[i][0],data[i][1],color = "b") plt.scatter(test_data[0][0],test_data[0][1],color='r') plt.show() #测试数据x=(0.1,0.3) #采用欧式距离进行计算 print("===============================距离计算================================") x = [[0.1,0.3]] distance = [] labels_wz = [] for i in range(len(data)): d = 0 d = sqrt((x[0][0]-data[i][0])**2 + (x[0][1]-data[i][1])**2) distance.append(d) labels_wz.append(i) print("计算的距离为:\n",distance) print("现在对应的标签位置为:\n",labels_wz) #按照升序排序,并取距离较小的前3个 print("===============================距离排序================================") for i in range(len(data)-1): for j in range(i+1,len(data)): if distance[i] > distance[j]: distance[i],distance[j] = distance[j],distance[i] labels_wz[i],labels_wz[j] = labels_wz[j],labels_wz[i] print("排序后的距离为:\n",distance) print("对应的标签的位置为:\n",labels_wz) print("取距离最近的3个值:",distance[0:3]) #进行投票表决 print("===============================表决投票================================") A = 0 B = 0 for i in range(len(labels_wz[0:3])): if labels[labels_wz[i]] == "A": A+=1 else: B+=1 print("投票为A的数量为:",A) print("投票为B的数量为:",B) print("\n对照初始图中红色点(测试点)与前两个标签为A的离的最近,所以我们的计算与图中所呈现的结果一致!") |
KNN算法运行结果查看