决策树概述¶
介绍¶
决策树(判定树)是一种常见的机器学习算法,它的思想十分朴素,类似于我们平时利用选择做决策的过程,也类似于问答猜测结果游戏,根据一系列数据,然后给出游戏的答案。
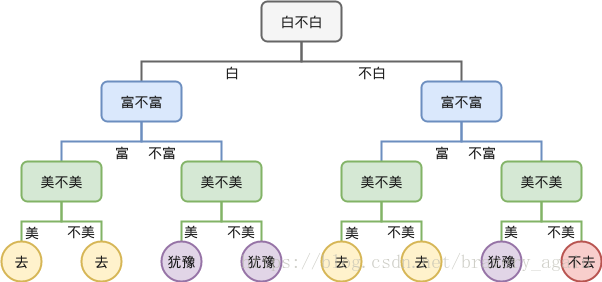
决策树学习的目标:根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
决策树学习的本质:从训练集中归纳出一组分类规则,或者说是由训练数据集估计条件概率模型。
决策树学习的损失函数:正则化的极大似然函数。
决策树学习的测试:最小化损失函数。
决策树学习的目标:在损失函数的意义下,选择最优决策树的问题。
决策树策略:自上向下,分而治之。
决策树种类:(1)分类树--对离散变量做决策树; (2)回归树--对连续变量做决策树
基本结构和概念¶
基本结构¶
一般由根节点、父节点、子节点和叶子节点构成。
1)子节点由父节点根据某一规则分裂而来,然后子节点作为新的父亲节点继续分裂,直至不能分裂为止;
2)根节点是没有父节点的节点,即初始分裂节点;
3)叶子节点是没有子节点的节点。
其他概念¶
(1)根结点(Root Node):它表示整个样本集合,并且该节点可以进一步划分成两个或多个子集。
(2)拆分(Splitting):表示将一个结点拆分成多个子集的过程。
(3)决策结点(Decision Node):当一个子结点进一步被拆分成多个子节点时,这个子节点就叫做决策结点。
(4)叶子结点(Leaf/Terminal Node):无法再拆分的结点被称为叶子结点。
(5)剪枝(Pruning):移除决策树中子结点的过程就叫做剪枝,跟拆分过程相反。
(6)分支/子树(Branch/Sub-Tree):一棵决策树的一部分就叫做分支或子树。
(7)父结点和子结点(Paren and Child Node):一个结点被拆分成多个子节点,这个结点就叫做父节点;其拆分后的子结点也叫做子结点。
算法步骤¶
步骤1:将所有的数据看成是一个节点(根节点),进入步骤2;
步骤2:根据划分准则,从所有属性中挑选一个对节点进行分割,进入步骤3;
步骤3:生成若干个子节点,对每一个子节点进行判断,如果满足停止分裂的条件,进入步骤4;否则,进入步骤2;
步骤4:设置该节点是叶子节点,其输出的结果为该节点数量占比最大的类别。
注:在决策树基本算法中,有三种情形会导致递归返回:
1 2 3 4 5 | 1) 当前结点包含的样本全属于同一类别,无需划分; 2) 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分; 3) 当前结点包含的样本集合为空,不能划分。 |
构造树过程处理¶
决策树的构造过程一般分为3个部分,分别是特征选择、决策树生产和决策树裁剪。
(1)特征选择:
特征选择表示从众多的特征中选择一个特征作为当前节点分裂的标准,如何选择特征有不同的量化评估方法,从而衍生出不同的决策树。
目的(准则):使用某特征对数据集划分之后,各数据子集的纯度要比划分钱的数据集D的纯度高(也就是不确定性要比划分前数据集D的不确定性低)
(2)决策树的生成
根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。这个过程实际上就是使用满足划分准则的特征不断的将数据集划分成纯度更高,不确定行更小的子集的过程。对于当前数据集的每一次划分,都希望根据某个特征划分之后的各个子集的纯度更高,不确定性更小。
(3)决策树的裁剪 决策树容易过拟合,一般需要剪枝来缩小树结构规模、缓解过拟合。
特征评估方法/划分准则¶
一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的"纯度"越来越高。其中最常用的三种准则:
-
信息增益准则(ID3)
-
信息增益率准则(C4.5)
-
基尼指数准则(CART)
剪枝处理¶
剪枝是决策树学习算法对付过拟合的主要手段。
过拟合原因:
1)噪声导致的过拟合:拟合了被误标记的样例,导致误分类。
2)缺乏代表性样本导致的过拟合:缺乏代表性样本的少量训练集作出的决策会出现过拟合。
3)多重比较造成的过拟合:复杂模型。
基本策略有"预剪枝" 和"后剪枝";
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;
后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
判断决策树泛化性能是否提升: 留出法 ,即预留一部分数据用作"验证集"以进行性能评估。
例如:在预剪枝中,对于每一个分裂节点,对比分裂前后决策树在验证集上的预测精度,从而决定是否分裂该节点。而在后剪枝中,考察非叶节点,对比剪枝前后决策树在验证集上的预测精度,从而决定是否对其剪枝。
两种方法对比:
1)预剪枝使得决策树的很多分支都没有"展开”,不仅降低过拟合风险,而且显著减少训练/测试时间开销;但,有些分支的当前划分虽不能提升泛化性能,但在其基础上进行的后续划分却有可能导致性能显著提高,即预剪枝基于"贪心"本质禁止这些分支展开,给预剪枝决策树带来了欠拟含的风险。
2)后剪枝决策树通常比预剪枝决策树保留了更多的分支。一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树,但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多。
特殊值处理¶
以上都是基于离散属性进行讨论,而连续属性的可取值数目不再有限, 因此,不能直接根据连续属性的可取值来对结点进行划分。此时需要进行连续属性离散化,最简单的策略是采用二分法对连续属性进行处理(C4.5)


泛化误差估计¶
- 再代入估计
再代入估计方法假设训练数据集可以很好地代表整体数据,因此,可以使用训练误差(再代入误差)提供对泛化误差的乐观估计。此情形下,决策树算法将简单地选择产生最低训练误差的模型作为最终的模型,尽管,使用训练误差通常是泛化误差的一种很差的估计。
- 结合模型复杂度
根据奥卡姆剃刀原则:“给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取”,复杂模型中的附加成分很大程度上是基于对偶然的拟合。
以下是把模型复杂度与模型评估结合在一起的方法: 悲观误差评估
使用训练误差与模型复杂度罚项的和来计算泛化误差,如:
设n(t)是结点t分类的训练记录数,e(t)是被误分类的记录数,则决策树T的悲观误差可表示为:
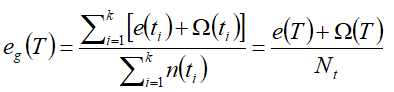
- 使用验证集
此方法中,不使用训练集来估计泛化误差,而是把原始数据集分为训练集和验证集,验证集用于估计泛化误差。通常是通过对算法进行调参,直到算法产生的模型在验证集上达到最低的错误率。
