基于项目的协同过滤¶
介绍¶
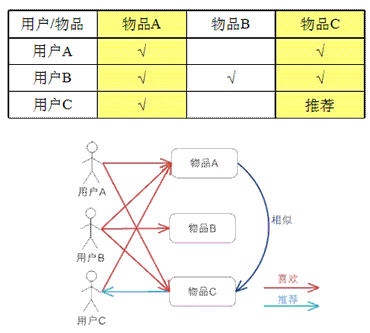
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。下图给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
推导¶
1)(建立用户-物品倒排表)
2)建立物品-物品的稀疏矩阵(共现矩阵)
3)相似矩阵
4)推荐
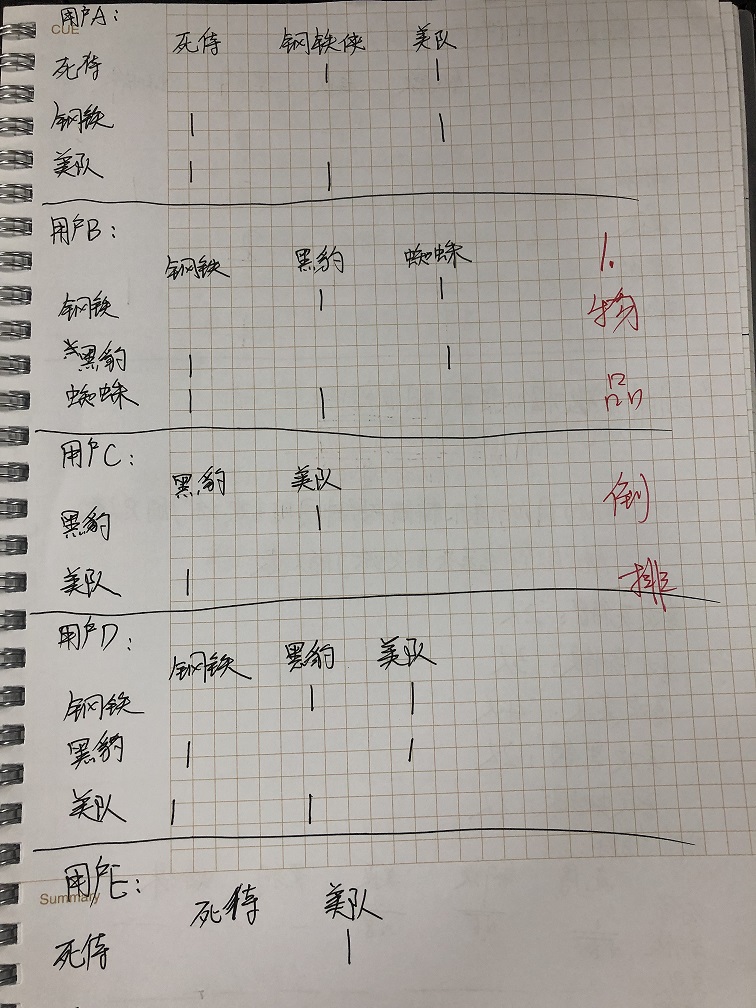
实例推导:


代码实现¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | from math import sqrt import operator import numpy as np #1.构建用户-->物品倒排 def LoadData(basis_data): data = {} for line in basis_data: user,score,item = line.split(",") data.setdefault(user,{}) data[user][item] = score print("物品倒排:\n",data) return data #2.构建物品与物品的共(同)现矩阵 def similarity(one_data): #构造物品的共现矩阵 N = {} #喜欢物品i的总人数 C = {} #喜欢物品i也喜欢物品j的人数 for user,item in one_data.items(): for i,score in item.items(): N.setdefault(i,0) N[i] += 1 C.setdefault(i,{}) for j,scores in item.items(): if j not in i: C[i].setdefault(j,0) C[i][j] += 1 print("构造的共现矩阵为:\n{}\n{}".format(N,C)) #计算物品与物品的相似矩阵 W = {} for i,item in C.items(): W.setdefault(i,{}) for j,item2 in item.items(): W[i].setdefault(j,0) W[i][j] = C[i][j]/sqrt(N[i]*N[j]) print("构造的相似矩阵为:\n",W) return W #3.根据用户的历史记录,给用户推荐物品 def recommandList(data,W,user,k,N): rank={}; for i,score in data[user].items():#获得用户user历史记录,如A用户的历史记录为{'a': '1', 'b': '1', 'd': '1'} for j,w in sorted(W[i].items(),key=operator.itemgetter(1),reverse=True)[0:k]:#获得与物品i相似的k个物品 if j not in data[user].keys():#该相似的物品不在用户user的记录里 rank.setdefault(j,0) rank[j]+=float(score) * w sort_data = sorted(rank.items(),key=operator.itemgetter(1),reverse=True)[0:N] print("推荐为:\n",sort_data) return sort_data #主函数 if __name__=='__main__': #A死侍 B钢铁侠 C美国队长 D黑豹 E蜘蛛侠 #1代表喜欢 user_item_data = ['A,1,a', 'A,1,b', 'A,1,d', 'B,1,b', 'B,1,c', 'B,1,e', 'C,1,c', 'C,1,d', 'D,1,b', 'D,1,c', 'D,1,d','E,1,a', 'E,1,d'] data = LoadData(user_item_data) W = similarity(data) #为用户A推荐2部电影 recommandList(data,W,"A",3,2) |
基于项目的协同过滤运行结果查看

